
Wisdom of the Crowd
Roast my app, Claude.
The Context
I’m doing some experiments with the Claude Code Agents and wanted to check out using sub-agents as report writers. I saw this in a YouTube video this week and thought it was an interesting idea.
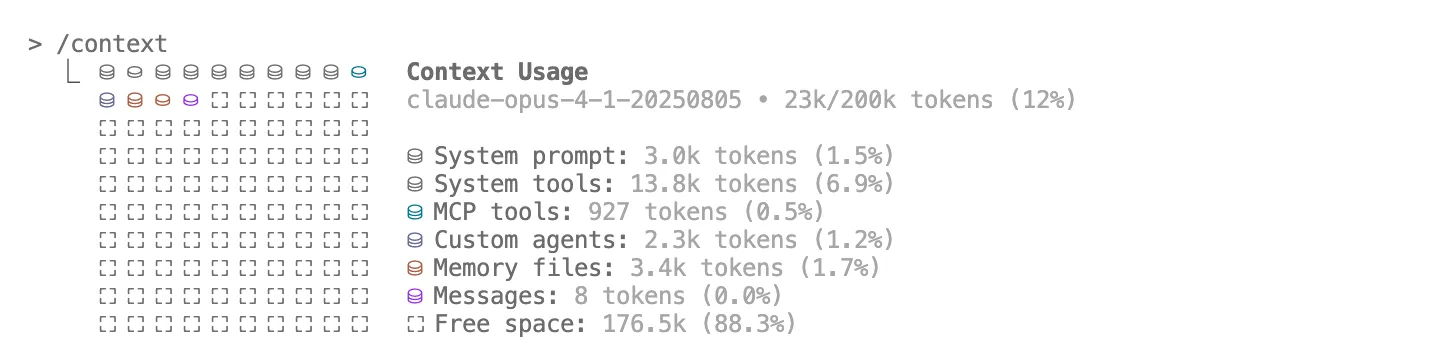
Before
After
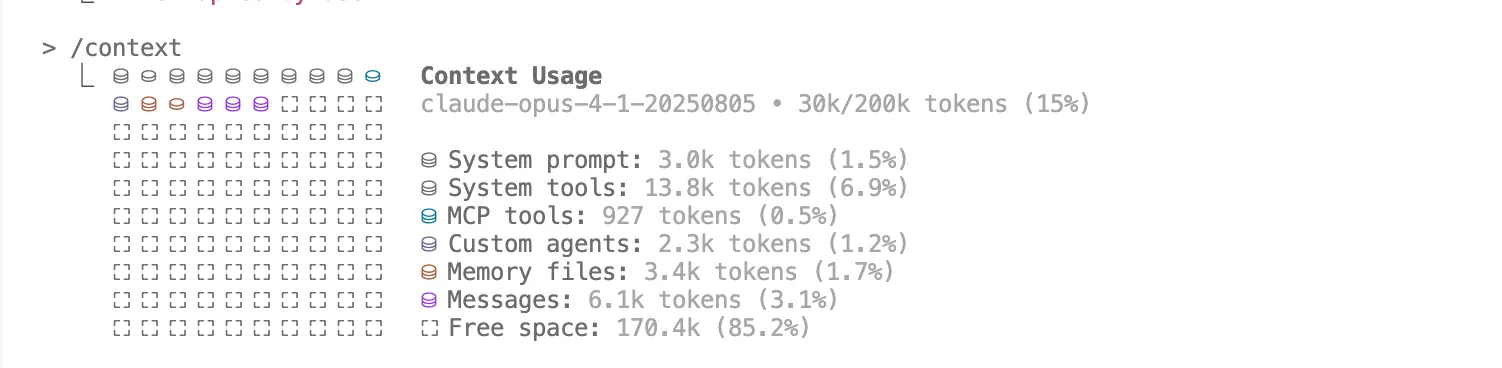
Considering each agent seemd to use around 50k tokens per task, I was delighted to see how much context I had left over for activities!
The Agents
- 📊 Monetization
- 🎨 UI Design
- 🏗️ Architecture
- ⚛️ Design Engineering
- 🧪 Testing
- 🔒 Security
The Prompt
I want you to talk to every agent that we have, the monetization, the mobile UI designer, the React Native Architect, the design engineer, the test engineer, and the security code reviewer, and ask them to generate a Markdown report in the .claude/docs folder rating this app on each of their area of expertise from 1 to 10 on up to 5 subtopics. And why they are rating it the way they are. They need to be brutally honest but reasonable in their assumptions that the app is just going to be a kind of like a simple side project app for awhile. So we don’t need to be enterprise grade. Any of them can take advantage of the high level repo researcher agent. When they are done, tell me. Do not read their documents yet.

The Roast
1. 📊 Monetization Evaluation
Score: 3/10
- AGENT: Found significant untapped revenue potential with disabled RevenueCat integration
- ME: What, you mean “opt-in ads” ISN’T a good strategy?
2. 🎨 UI Design Evaluation
Score: 7.2/10
- AGENT: Strong theme system but needs professional icons instead of emoji
- ME: Yes. Vibe coding LOVES emoji.
3. 🏗️ Architecture Evaluation
Score: 7.5/10
- AGENT: Well-structured modular architecture, appropriate for current scale
- ME: Perfect. I’ll take this as a compliment.
4. ⚛️ Design Engineering Evaluation
Score: 7.2/10
- AGENT: Solid foundations but critical accessibility gaps
- ME: Reasonable, lots of small todos here for progress.
5. 🧪 Testing Evaluation
Score: 4/10
- AGENT: Only 12% test coverage, needs significant improvement
- ME: React Native isn’t super fun to test.
6. 🔒 Security Evaluation
Score: 4/10
- AGENT: CRITICAL: lol, nice try
- ME: Nice try, Snowden. I’ll work on these before launch obviously.